Hackers vs. Applications
A homeowner thinks to secure himself using a lock that can only be opened with the correct key. The burglar may ignore the complexities of lock-picking and try to slide a flexible plastic sheet through the gap between the door and the door jamb to push the catch back. In other words, the burglar attacked the door in a way that was unforeseen.
Similarly, hackers break into applications by addressing normal access points in ways that developers didn’t intend or foresee. A very common method of forcing entry is by buffer overflow. The tools used most often by hackers to discover buffer overflow weaknesses; fuzzers.
Developers produce applications that, to a greater or lesser degree, adheres to a protocol as closely as possible. QA then tests application functionality against that protocol in the perfect world of the testing laboratory. But when the application is released, hackers will bash away at it with every possible corrupted form of the protocol to create an error in the application. By pushing at the edges of the envelope of the protocol they may find a way to trip up the application and create a buffer overflow, the most frequently leveraged design error.
Subverting Input Using a Buffer Overflow
The goal for hackers is to subvert the official entry points of any application and use them to possibly crash it or, even better, to open up a way to inject new code to allow the hacker to take control of the server. one of the most common methods of subversion is the buffer overflow. It is common because all incoming application data must be stored in a buffer so that it can be processed by the application and this is the key to opening up an entry point.
In November 1988, the Morris worm gave the world a reality check on how hackers can disrupt computer systems and inject disruptive code using weaknesses in software design. The worm exploited flaws in BSD Unix running on DEC Vax and Sun servers and succeeded in bringing 10% of the internet’s servers down. This alerted the world to the dangers of buffer overflows.
What is a Buffer Overflow?
Buffer overflows occur when malformed data or oversized data fields are fed into an application buffer. The program is expecting input that complies with a specific protocol, but what happens if the input does not comply? In many cases the answer is that unexpected input will exceed the allowed space in input buffers and this disrupts the execution of the application in some way. This brute-force technique has proven to be a rich source for code injection on many applications and operating systems. In the years since the Morris exploit it still figures highly in the list of successful attack methods.
It may seem strange that after so many years there are still buffer overflow loopholes that can be exploited but this has a lot to do with the way in which applications are tested before finally being released. The pre-launch quality assurance (QA) checking looks for problems by testing application functionality. QA answers the question: Does it work as intended? To prove this, QA typically sticks to the protocol standards and often finds enough to fix within that range of input that there just isn’t time to wander off the reservation into corrupted forms.
The Problem At-Hand:
The problem is that developers are focused on getting their new application to work and are never given time to then figure out how they might be broken. QA is tasked with making sure the application works as intended and isn’t given the time or budget to manually check every possible variation on how data might be fed into the application. This becomes obvious when we see that even the best software companies in the world rush out products and then rush out security fixes almost immediately after an application has been released for sale. There are just too many variables to test by hand and too little time.
How Do Fuzzers Work?
How are hackers finding buffer overflow opportunities missed during development and QA? A wide range of tools have been developed by the hacker community to enable the rank and file to find new exploits. These tools, fuzzers, work by creating and feeding a wide range of false or corrupted inputs looking for a combination that will break the application. The production of these tools has become a small industry of its own. The QA world has attempted to adapt these rough and ready hacker tools into their test processes with some success, but also with many headaches.
Most of these hacker tools are focused on a single type of code weakness or on just a single protocol or even on a single application. To test every new product for every weakness may require that QA acquire and become proficient at using dozens of fuzzers, few of which are well developed and none of which come with much documentation or support. Additionally, new fuzzers are appearing all the time.
QA Headache – Keeping Up With the Hackers
The QA department faces a huge problem. Hackers outnumber QA staff and they are able to specialize in particular forms of exploit. By contrast, a QA expert has to be a jack-of-all-trades and it is a constant battle to keep up with the latest hacker tools and techniques.
The solution is to arm QA with a single, easy to use, multi-protocol, well documented and supported tool that bundles all of the tests and attacks done by hundreds of hacker-developed fuzzers. According to a recent study by the Bonn-Rhein-Sieg University of Applied Sciences there are more than 250 Fuzzers. 25% test web applications and 45% test one or more network protocols. File formats are fuzzed by 15% and APIs just 7%. In the entire world there are only two multi-protocol, environment-variable fuzzers, of which our beSTORM is one.
QA has an advantage over hackers: With direct access to the application and its host, they can monitor the effects of fuzzing closely. Valuable information can be gained by using a suitable debugger such as the open sourced OllyDbg for Windows-based systems or the GDB debugger that comes free with most Unix systems. Specific parameters can also be measured exactly, such as memory usage, network activity, file system actions and for Windows, registry file access. Tools for these purposes can be found as part of the Sysinternals Suite, now owned by Microsoft.
Hackers lack this refined option. Instead, monitoring network traffic may be the only source of information on a system being attacked. The absence of reply packets, the presence of unusual packets or the absence of a service for long periods may be the only indicators of a crash.
Why Do We Need Fuzzing?
Fuzzing tools are vital for finding buffer overflow weaknesses because they automate and document the process of delivering corrupted input and they watch closely for unexpected response from the application. For example, transmitting data fields of various sizes by incrementing field lengths is a task that can easily be handled by a fuzzer and is just not viable by hand. Similarly, a ‘smart’ fuzzer like beSTORM will try packets with malformed headers, by manipulating packet content and providing the kind of data that the application may be looking for, using &, <, >, full stops and commas within email applications, or typical URL symbols for HTTP servers.
Fuzzing Techniques
Fuzzing techniques fall into three basic types: session data, specialized, and generic.
Session Data Technique
Is the simplest type because it transforms legal data incrementally. For example, the starting point could be a SMTP protocol: mail from: sender@testhost
This would then be sent in the following forms to see what effect they have:
- mailmailmailmail from: sender@testhost
- mail fromfromfromfrom: sender@testhost
- mail from:::: sender@testhost
- mail from: sendersendersendersender@testhost
- mail from: sender@@@@testhost
- mail from: sender@testhosttesthosttesthosttesthost
Specialized fuzzers
These fuzzers target specific protocols. Typically these would be network protocols such as SMTP, FTP, SSH, and SIP but must also now include file types such as documents, image files, video formats, and Flash animations.
Second generation fuzzers allow the user to define the packet type, the protocol, and the elements within it to be fuzzed. Their flexibility is balanced by the fact that users have to be aware of the vulnerabilities to be tested and may overlook some. It is crucial that every element in the protocol is tested, no matter how unimportant it may seem. In the above example, it may seem pointless to repeat the colon but this could be the flaw that cracks the app. The lesson is that nothing should be taken for granted.
Smart fuzzers
Effectively the third generation – come pre-loaded with testing modules that will target protocol weaknesses and also ensure that every element of a protocol is tested. They start with the input most likely to crash an application and then branch out to (potentially) millions of permutations. Coverage of the full test space is so close to 100% that when an application is fuzzed well in QA and fixed, hackers are likely to give up trying to break it and find easier entry points in some other application.
Defending Against Buffer Overflows
Developers are not infallible. When buffer overflows started to hit the headlines, many C programmers switched to using bounded string operations as a cure-all. Unfortunately, the strncpy() command was often implemented incorrectly resulting in the Off By One error. This was caused by setting a buffer size to, say, 32. It sounds logical enough but the input field has to have a null value terminator and that has to be allowed for in the character count and added by the application. The null marks the buffer’s edge, but would be overwritten by an apparently legal 32 character input. This means that the boundary between neighboring buffers disappears and future accesses may treat the two strings as a larger single buffer and open up the possibility of a buffer overflow exploit where one may not have existed before.
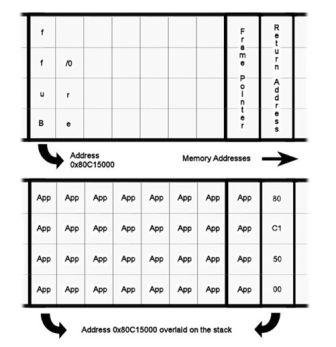
Figure 1. The buffer in the upper picture is filled with application code suffixed by a four byte address which overflows onto the stack to alter the return address.
Once a weakness has been found and documented by QA their job is almost over, barring a fix being devised and issued. For the hacker, however, the real task is just beginning. A successful fuzz attack typically ends with an application crash – not very useful, unless disruption is the aim. But the crash indicates that some executable bytes have been overwritten with nonsense. The chances are that this is probably a stack error and a return address has been corrupted causing the application to jump to some arbitrary memory location. Before being overwritten with nonsensical input, this location used to be a pointer to the continuation of the legally running application code.
Stack-Based Buffer Overflows
Once a crash has been produced, the hacker carefully crafts an oversized buffer input to overwrite the jump address at the top of the stack with a pointer to executable code stored elsewhere in RAM instead of just arbitrary bytes as before. Usually the pointer is set to the beginning of the buffer. When writing the new input, the hacker uses padding to ensure the four bytes carrying the jump location is correctly placed on the stack.
Rather than just any kind of padding, the bytes placed by the hacker form a shellcode routine in assembly code. When the pointer redirects program execution to the buffered code, the attacker has taken control of program execution and can take control of the server, assuming the interrupted application had root, or administrator, rights. Obviously, the larger the buffer, the larger the chunk of code that can be inserted.
Fuzzing into the Future
The growth of the use of fuzzers and fuzzing as a QA tool has been remarkable. From the QA perspective it offers a very effective way to discover flaws early. For attackers it presents a way to attack servers that would otherwise be difficult to penetrate.
The number of fuzzer programs used by hackers is increasing in both specialization and subtlety. As tools become more sophisticated and successful hacks more frequent, developers become bogged down with patch requests. This will result in rising maintenance costs and a point can be reached where a trade-off between increasing the security and financial considerations may start to affect the reliability of software. There is a danger that vulnerability detection will become far more reactive than proactive.
Catching Vulnerabilities During Development
The solution is to catch application flaws during development using the best fuzzer you can get – when correction is relatively easy and far less expensive.
Fuzzing techniques can be used in QA to find all manner of security vulnerabilities. Apart from highly publicized buffer overflows, there are related integer overflows, race condition flaws, SQL injection, and cross-site scripting. In fact, more vulnerabilities can be detected using a smart, stateful, grammar-based, generation-based fuzzer, like beSTORM, than with any other single tool.
Vulnerability testing using fuzzers is more important now than ever before as financial gains from professional hacking become more attractive. The current pressures on in-house departmental QA to keep up with fast moving changes in the breadth and scope of exploits is now making it vital that they move toward commercial grade fuzzers – single tools that can efficiently test every product and protocol in production.